
Yakread's ranking algorithm
Continuing the Yakread rewrite, last weekend I rewrote the part of Yakread's ranking algorithm that merges your newsletter/RSS subscriptions and your bookmarked articles into a single personalized feed. This is basically the “heart” of Yakread, the whole reason I wanted to make the app in the first place. (And it's about 200 lines of code. Funny how much additional stuff has to be layered on top just to make those 200 lines of code usable.)
This part of the algorithm does three main things: it picks which subscription posts to recommend; it picks which bookmarked articles to recommend; and it decides in what order to mix those posts and articles together. The end result is a batch of, say, 30 items which will be displayed to the user on their For You feed.
(Instead of “posts” and “articles”, I typically use the more general term “item”, which is a common term for things that recommender systems recommend.)
Bookmarks
First we take all your unread bookmarked items and sort them by how many times you've scrolled past them previously. For items with the same number of “skips,” we sort by how recently the item was bookmarked. “Fresher” items (those that have been skipped less and were bookmarked more recently) come first.
To shake things up a bit, we then partially shuffle the items. I wrote a simple shuffle algorithm that has a bias toward leaving items close to their original spots. There's a “randomness” parameter (I'll call it p) you can set between 0 and 1: 0 will make the algorithm behave like a completely random shuffle, and 1 will leave the items in their original order.
I've set p to 0.1. That might make it sound like the items will be mostly-but-not-completely in random order, minimizing the impact of the initial sort-by-freshness. However, the parameter affects the randomness in a non-linear way. The following graph approximately shows the probability that the first item in the shuffled list will be one of the first ten items in the original list (y axis), given different values for p (x axis):
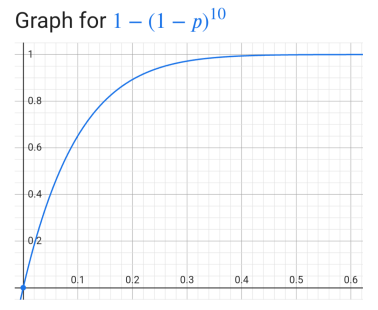
(The formula technically needs one more term that takes into account the size of the original list; however, if the original list is at least 50 ish items then that term is pretty small.)
So for p = 0.1, there's a 65% chance the first bookmark item will be one of the ten freshest items. I might tweak that parameter based on gut feel after I start using the rewritten app.
The final step for bookmark recommendations is that we look at the items’ URLs and only recommend at most one bookmark per website (host). I added this filter because about six months ago I bookmarked a few hundred articles from a particular website, and they still dominate my Yakread feed. I already had a filter like this for subscriptions (each batch of subscriptions includes at most one item per subscription).
Subscriptions
Subscription recommendations have two main steps: first we pick a list of subscriptions to recommend (and in which order); then pick one item from each subscription.
I'll knock out the second step first: it's basically the same as the bookmark algorithm. We sort the items by freshness, do our randomish-shuffle thing, then pick the first item in the resulting list.
To pick the subscriptions in the first place, first we calculate an “affinity score” for each subscription that represents how much you like it. I look at the 10 most recent interactions you've had with each subscription:
- view: you clicked on this item for the first time.
- skip: you clicked on a subsequent item in the For You feed but not this one.
- like / dislike: you clicked the “favorite” / “not interested” button while viewing the item.
To turn those interactions into a single score, I’ve currently assigned somewhat-arbitrary weights to each interaction (e.g. +2 for a view and -1 for a skip) and then I take the “beta distribution expected value,” which means: if you’re flipping a coin and +2 represents getting heads twice while -1 represents getting tails once, what is the probability of getting a heads next? Also, to help new subscriptions get more exposure, I give them a starting score of +3.
This approach is simple and seems to work well enough (when I use the score to query for my own top/bottom 10 subscriptions, the results seem reasonable). It would be nice to remove the need for me to pick weights though. At some point I might try using some kind of machine learning model that can take a list of interactions and predict the probabilities of what the next interaction will be (apparently an RNN would work). Then the score can be the probability that the next action is positive (i.e. a view or a like).
After sorting the subscriptions by their affinity score, we give some extra priority to subscriptions that the user has manually pinned. We split the subscriptions into two lists, pinned and unpinned. Then we interleave those those lists back into a single list by repeatedly picking from which of the two lists to take the next interleaved subscription.
Most of the time we simply pick whichever subscription (pinned or unpinned) has the highest affinity score. But 30% of the time, we pick the next pinned subscription regardless of affinity.
After doing all that, we do our random-ish shuffle thing on the subscriptions list, then we move on to the step described above where we pick an item from each subscription.
Interleaving subscriptions and bookmarks
At this point we have a list of subscription items and a list of bookmarked items, and we need to interleave them into a final list which will be shown to the user. An easy and not terrible approach would be to flip a coin for each item in the final list: heads and it comes from subscriptions, tails and it comes from bookmarks. And at a base level, that is what I’m doing.
However, that could have issues if the user has more subscription items than bookmarks or vice versa. If you’ve already scrolled past all your unread bookmarked items several times but you have a bunch of new subscription items, we should probably lean towards recommending the subscription items.
I do this by comparing the two lists pairwise and selecting an item via weighted random choice based on how many times they’ve been previously skipped (i.e. scrolled past in the For You feed). e.g. if the first bookmark item has been skipped twice and the first subscription item has been skipped once, then there’ll be a 60% chance we select the subscription item and a 40% chance we select the bookmark item.
Published 7 Apr 2025
